Decision Trees
What are Decision Trees
Decision Trees (DTs) are a supervised learning technique that predict values of responses by learning decision rules derived from features. They can be used in both a regression and a classification context. For this project, decision trees are used in the classification context. Decision tree learning is a method commonly used in data mining. The goal is to create a model that predicts the value of a target variable based on several input variables.
Decision Trees in Python
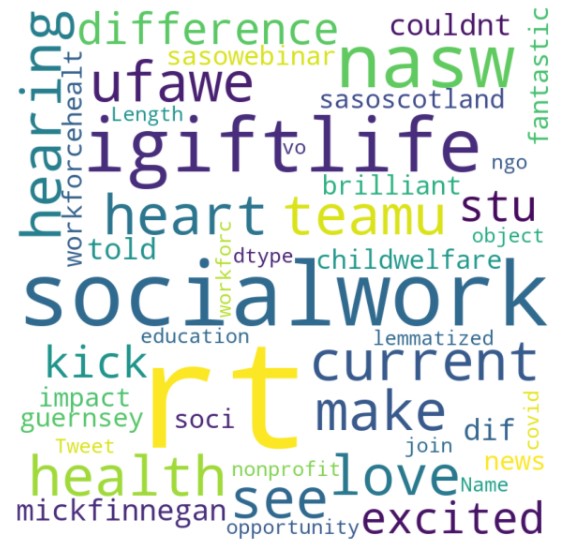
The decision trees are created using text dataset in Python.The tweets are extracted on the hashtag "social worker" and hashtag "covid" . The motive behind collecting this text data was to understand the opinion of people regarding social work and different tweets regarding covid. To get a quick overview of the data, a wordcloud has been made.

Cleaning and formatting the dataset to the required format
There are a lot of unwated columns in the dataframe. These columns are dropped from the dataframe, retaining only the necessary columns. The stopwords are removed and the text is tokenized, lemmatized and stemmed. Countvectorizer is applied on the data to convert it to numerical format. Checking the balance of the label is very important before performing decision trees, as unbalanced dataset may lead to over or underfitting.
Model Building
The code to build the model can be found here
Before building the model, the dataset is split into training and testing sets. The split ratio is 0.75 of the total data in the training set and 0.25 data in the testing set. Three different decision trees are created. The Decision Trees differ due to hypertuning of different parameters. Mainly criterion (entropy, gini), splitter (best, random) ,max_depth is tuned.
Decision Tree 1
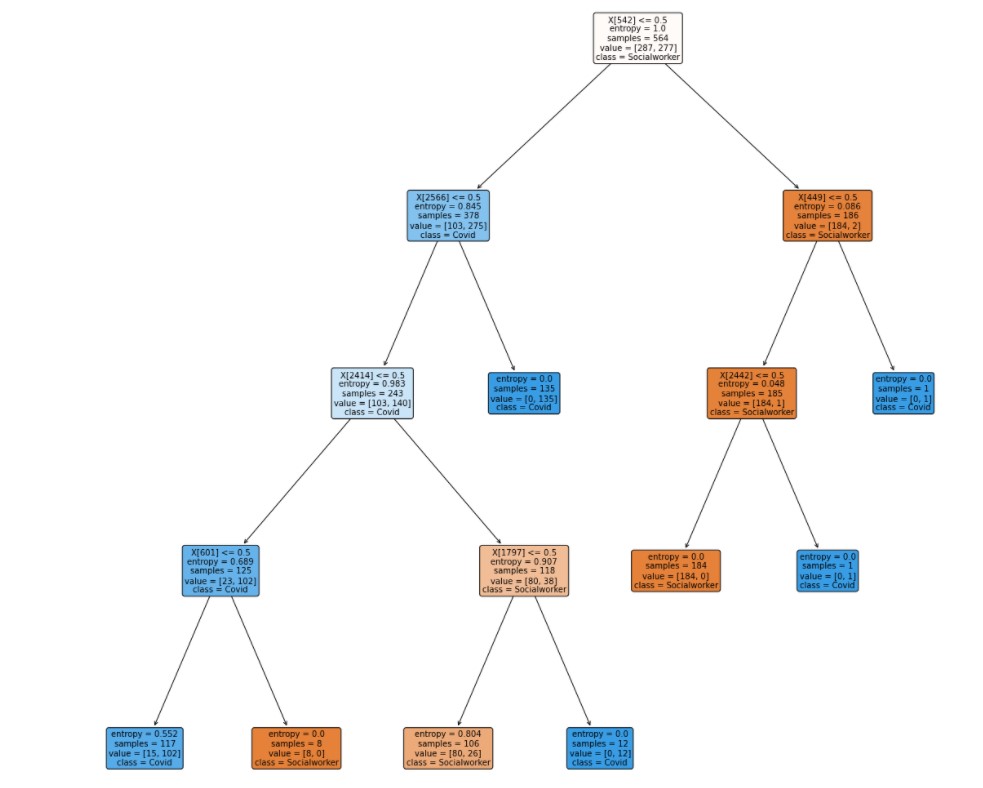
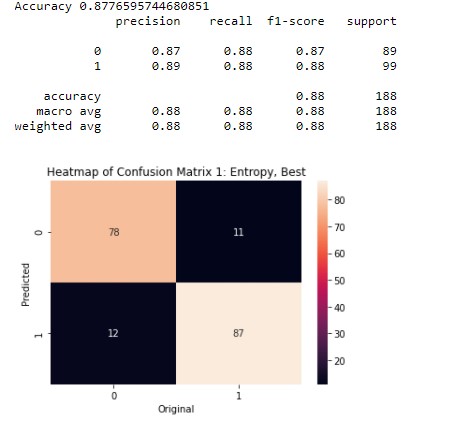
This is the first decision tree. In this tree the hyperparameter are criterion = "entropy", splitter = "best",max_depth = 4. In this tree, the accuracy is 88%.
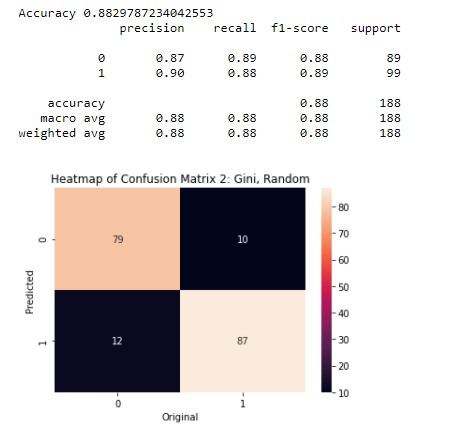
Decision Tree 2
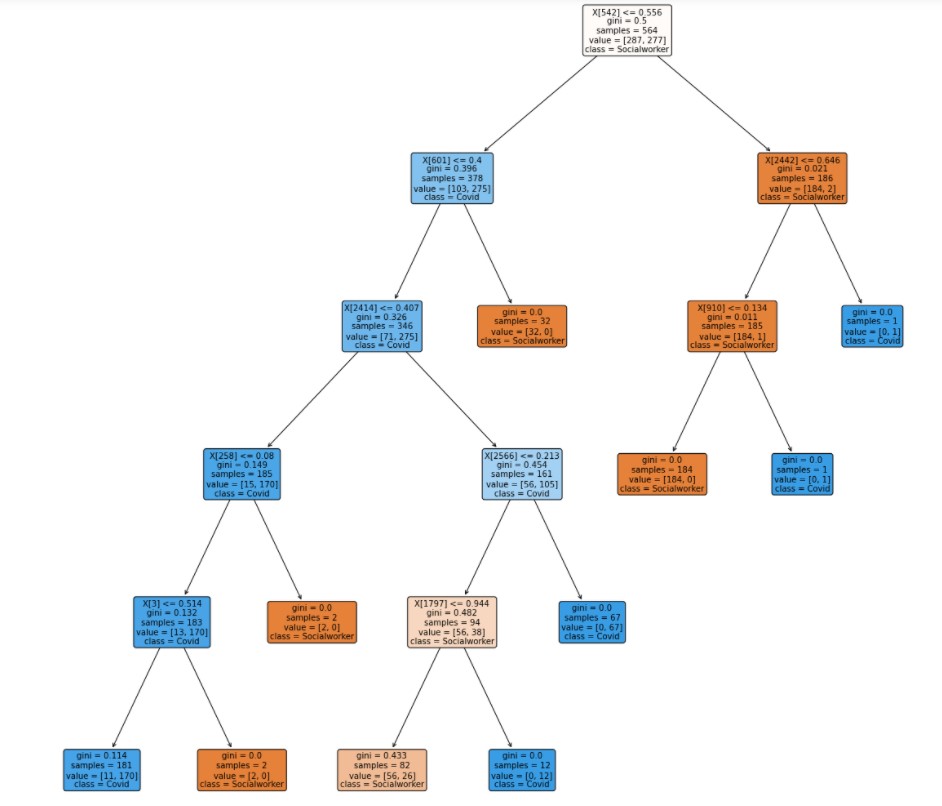
This is the second decision tree. In this tree the hyperparameter are criterion = "entropy", splitter = "best",max_depth = 4. In this tree, the accuracy is 88%.
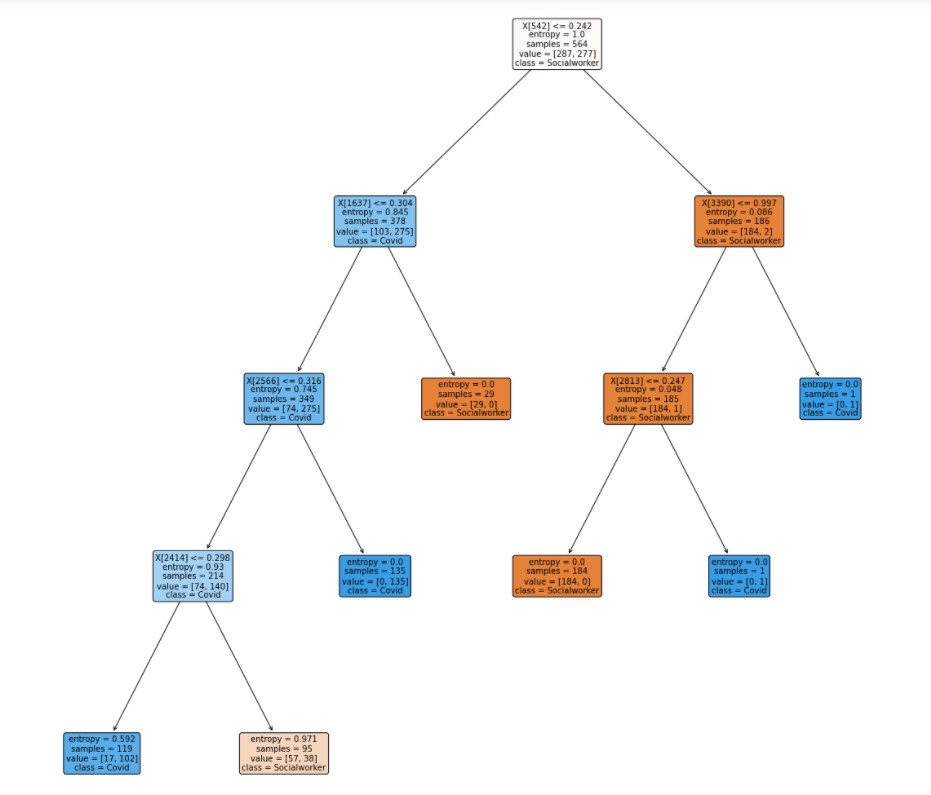
Decision Tree 3
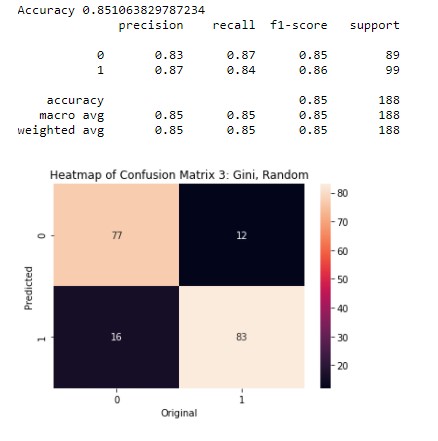
This is the third decision tree. In this tree the hyperparameter are criterion = "entropy", splitter = "best",max_depth = 4. In this tree, the accuracy is 85%.